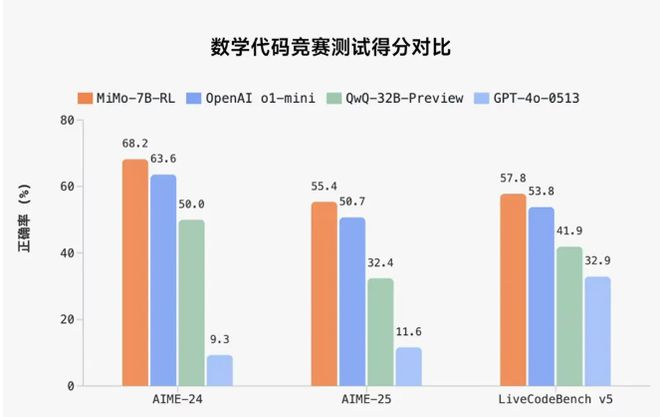
 AI的比赛很强大,小米也加入了战斗! 4月30日,小米推出了Big Moda Mimo的开源,重点关注推理能力,超过OpenAI O1-Mini,而阿里巴巴在数学推理中关闭了32B级QWQ,并仅使用7B参数对代码竞争进行了审查。根据小米的说法,小米Mimo诞生开始时探索的主要问题是刺激该模型的潜在认识。该模型接受了训练后的培训,以完全提高其概念能力。国内外的AI竞赛变得越来越激烈。本周,阿里巴巴发布了Qwen 3,马斯克正式宣布了Grok 3.5。根据以前的媒体报道,小米建立了Wanka GPU的一群人,并引入了AI的领先才能,显示了大型模型的全部投资。性能下降:少量参数实现了很大的功能。小米MIMO模型最引人注目的特征是在公共分析中h推理(AIME 24-25)和代码竞争(LiveCodeBench V5),MIMO仅使用7B参数量表,该量表超过了封闭的源源模型O1-Mini和Alibaba的较大的开放源QWQ-32B preview。在与学习训练(RL)数据(RL)的相同条件下,MIMO-7B更为明显的是,MIMO-7B显示了数学和代码领域的潜在刺激性研究,这些研究在行业中广泛领先于其他模型,包括众所周知的增强研究,例如DeepSeek-R1-Dist-7B和QWEN2.5--32B。技术密钥:根据Youy小米的训练和训练后双轮驱动,MIMO模型的成功是偶然的,但来自训练前和训练后两个阶段的多层次变化。在训练前阶段,小组团队专注于富含推理模式的语料库开采,并综合了约200B代币的推理数据。培训过程采用了三阶段的方法来逐渐增加训练的困难并训练总计25T令牌,该令牌位于相同尺寸的最高级别。改变训练后阶段更为关键。小米团队提出了测试的困难驱动了奖励机制,从而有效地解决了算法问题的广泛奖励问题。同时,引入了简单的重新采样数据方法,从而显着提高了学习训练的稳定性。在框架级别上,他们设计了无缝控制系统,该系统将教育训练速度的速度提高了2.29次,验证速度为1.96倍。除了技术外,小米对接口新闻的全面AI投资方法还建立了自己的GPU 10K群集,并将对AI模型进行大量投资。一个熟悉这方面的人透露该计划已经实施了几个月,小米创始人雷・朱尼亲自参加了领导。人类强调:就AI硬件而言,最重要的是,手机而不是这是眼镜,小米不可能在这个领域中全部。小米的AI人才布局也加速了。 12月20日,Pangdeek开源模型DeepSeek-V2开发人员之一的首个财务日报Luo Funi将加入小米,或在小米AI实验室工作以统治小米模型团队。 Lu Furi是MLA(多头潜在注意力)技术的主要开发商之一,该技术在降低使用大型模型的成本方面起着重要作用。 [资料来源:华尔街新闻官]
AI的比赛很强大,小米也加入了战斗! 4月30日,小米推出了Big Moda Mimo的开源,重点关注推理能力,超过OpenAI O1-Mini,而阿里巴巴在数学推理中关闭了32B级QWQ,并仅使用7B参数对代码竞争进行了审查。根据小米的说法,小米Mimo诞生开始时探索的主要问题是刺激该模型的潜在认识。该模型接受了训练后的培训,以完全提高其概念能力。国内外的AI竞赛变得越来越激烈。本周,阿里巴巴发布了Qwen 3,马斯克正式宣布了Grok 3.5。根据以前的媒体报道,小米建立了Wanka GPU的一群人,并引入了AI的领先才能,显示了大型模型的全部投资。性能下降:少量参数实现了很大的功能。小米MIMO模型最引人注目的特征是在公共分析中h推理(AIME 24-25)和代码竞争(LiveCodeBench V5),MIMO仅使用7B参数量表,该量表超过了封闭的源源模型O1-Mini和Alibaba的较大的开放源QWQ-32B preview。在与学习训练(RL)数据(RL)的相同条件下,MIMO-7B更为明显的是,MIMO-7B显示了数学和代码领域的潜在刺激性研究,这些研究在行业中广泛领先于其他模型,包括众所周知的增强研究,例如DeepSeek-R1-Dist-7B和QWEN2.5--32B。技术密钥:根据Youy小米的训练和训练后双轮驱动,MIMO模型的成功是偶然的,但来自训练前和训练后两个阶段的多层次变化。在训练前阶段,小组团队专注于富含推理模式的语料库开采,并综合了约200B代币的推理数据。培训过程采用了三阶段的方法来逐渐增加训练的困难并训练总计25T令牌,该令牌位于相同尺寸的最高级别。改变训练后阶段更为关键。小米团队提出了测试的困难驱动了奖励机制,从而有效地解决了算法问题的广泛奖励问题。同时,引入了简单的重新采样数据方法,从而显着提高了学习训练的稳定性。在框架级别上,他们设计了无缝控制系统,该系统将教育训练速度的速度提高了2.29次,验证速度为1.96倍。除了技术外,小米对接口新闻的全面AI投资方法还建立了自己的GPU 10K群集,并将对AI模型进行大量投资。一个熟悉这方面的人透露该计划已经实施了几个月,小米创始人雷・朱尼亲自参加了领导。人类强调:就AI硬件而言,最重要的是,手机而不是这是眼镜,小米不可能在这个领域中全部。小米的AI人才布局也加速了。 12月20日,Pangdeek开源模型DeepSeek-V2开发人员之一的首个财务日报Luo Funi将加入小米,或在小米AI实验室工作以统治小米模型团队。 Lu Furi是MLA(多头潜在注意力)技术的主要开发商之一,该技术在降低使用大型模型的成本方面起着重要作用。 [资料来源:华尔街新闻官]






 推荐文章
推荐文章









){kind=link}
){kind=link}
){kind=link}
){kind=link}